In the past, a control engineer would look at the description files of all of the different devices in the factory. One by one, these devices would be combed through to discern the format of the data provided. This, of course, is unique for each individual device. To put it simply, this process was a bit of a cumbersome task just to enable communication between a controller and a device.
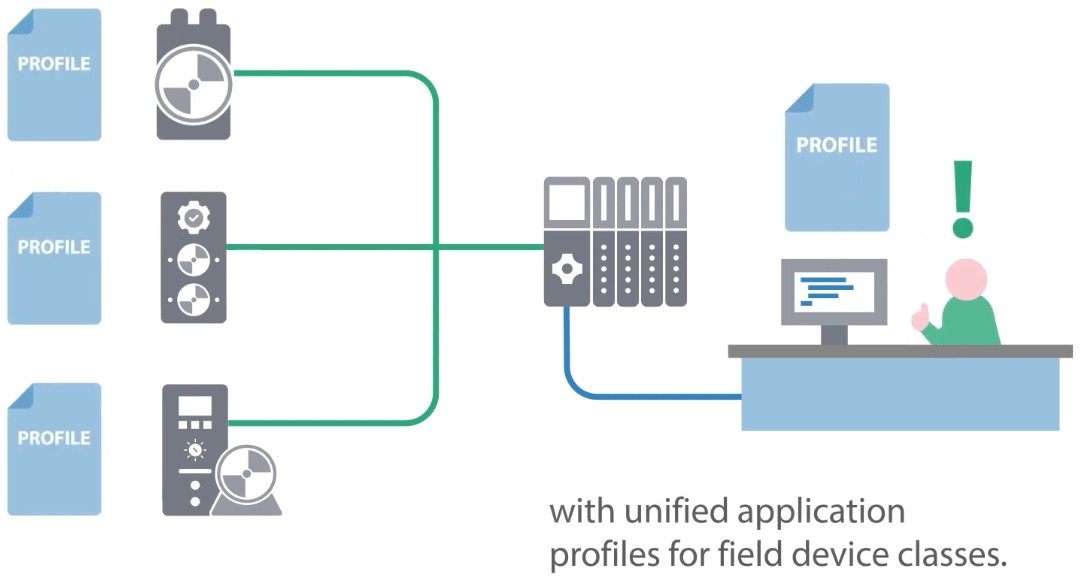 Things became a little easier with the introduction of application profiles. Application profiles standardize the format and structure of data from a family of devices. For example, the way data is presented from all drives, independent of vendor, is the same. Then, when the control engineer configures the drive per the application profile, the data is more quickly and easily available for programming.
Things became a little easier with the introduction of application profiles. Application profiles standardize the format and structure of data from a family of devices. For example, the way data is presented from all drives, independent of vendor, is the same. Then, when the control engineer configures the drive per the application profile, the data is more quickly and easily available for programming.
Not all of the data available from devices is needed by the controller for running the plant. As smarter devices come on the market, even more data can be made available, though not necessarily used in the day-to-day automation. In these instances, edge gateways are becoming an increasingly popular, and, in fact, preferred way to access that data. However, the presentation of the data from different edge gateway manufacturers could vary. Here, information models like OPC UA, can be helpful to standardize data for higher level IT systems.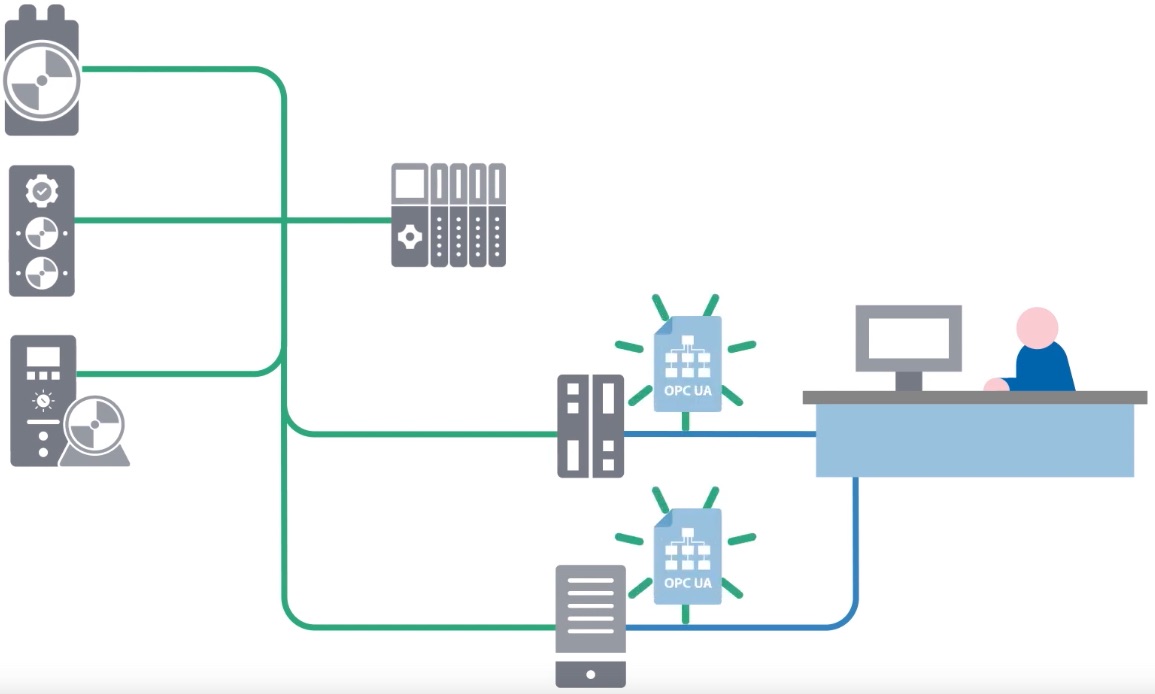
To hasten this process, companion specifications are being written. These companion specifications take the information models in application profiles and translate them to OPC UA information models.
But what about devices that don’t have an associated application profile or are connected to the edge gateway via a different fieldbus? For these situations, unified libraries for all possible values and attributes exist. Examples include ECLASS, umati, AutomationML, PA-DIM, and more. They help integrate these data into the information model. With the application profiles, general companion specifications, and unified libraries, a complete information model of the devices can be constructed.
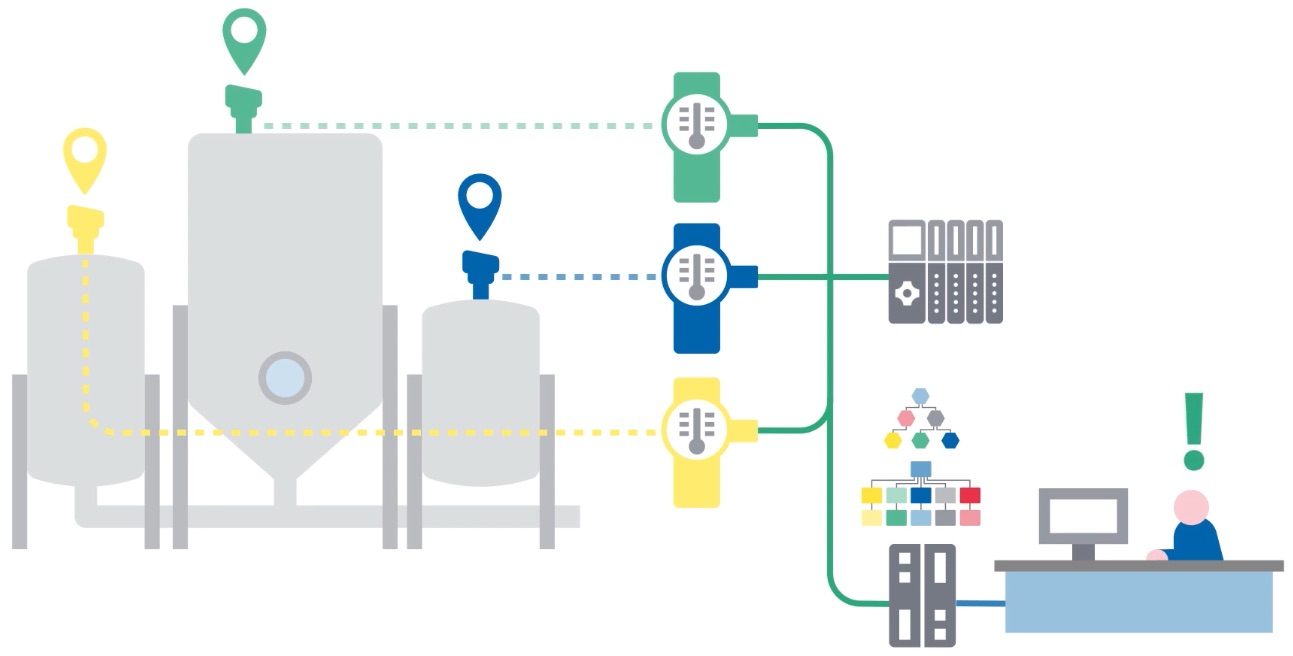 It is often the case that multiple devices of the same type are installed in a plant. An engineer then needs an easy way to determine the location of each specific device to map its data to the correct process or asset in the production. An information model of the plant helps locate the devices. Then, relations can be defined between the device information model and the plant information model, and the data can be mapped to specific assets.
It is often the case that multiple devices of the same type are installed in a plant. An engineer then needs an easy way to determine the location of each specific device to map its data to the correct process or asset in the production. An information model of the plant helps locate the devices. Then, relations can be defined between the device information model and the plant information model, and the data can be mapped to specific assets.
The most critical part of the information model is that it is machine readable. This saves time preparing the data for use. It allows the data to be used automatically due to its standardized structure and harmonized semantics. Projects revolving around asset management, analytics or condition monitoring can therefore more quickly be brought online. For these reasons, information models are becoming an area of focus for us at Profibus & Profinet International (PI) over the coming months.